toc
- Using Git as a database
- Using shell scripts and pandoc instead of a big boy HTML parser
- Doing everything on a Raspberry Pi running cronjobs in my closet
- “Higher order” dependency management
- “Just use Python”-ing all the things
- Using CC Zero whenever possible
- The culture that is the CLIzation of everything
Since wiping my Github over a year ago I’ve taken a much more, let’s say, impatient approach to my work.
I have a lot of things I want to do, and a lot of things I want to see exist. Most of the things I want to see exist are niche enough that they won’t exist if I don’t make them. So, over time, I’ve refined a few anti-patterns and anti-techniques that let me build the worst possible version of a thing I myself will just barely put up with using. Let’s dive into some of them.
Using Git as a database
A few months after moving to Finland almost illegally and reading a really good book I promptly threw everything I had learned about elegant and composable design in the garbage and started making myself a flashcard deck to learn Finnish. The result was surprisingly popular, popular enough that I even made a sequel which I still use mostly unchanged to this day.
There’s just one problem: I lost the SQLite databases I used to build both of these databases. Good on me for not overengineering even more, I guess, and using a whole Postgres server for my dinky little web-scraping experiments, but I really do not have the time anymore to go back and run the code I used to create these databases from Tatoeba.
Not so anymore. Now when I want to scrape web data, I scrape directly to a GitHub repo until it becomes painfully obvious this is a bad idea. (Hat tip to Simon Willison’s Weblog for pioneering the technique! You are an inspiration to me to do better, even if I don’t.)
Using shell scripts and pandoc instead of a big boy HTML parser
It gets worse. I not only use Git as a database, I make intermediate Git databases, out of the raakaa-aineita, by wholesale git submodule-ing the original database time and time again until I get what I actually want. Thank god ``git submodule –recursive` is not the default, we would be here all day.
Now HTML is a pretty nice format, actually. I could use BeautifulSoup and Python to very easily extract whatever I wanted from the webpage. It would probably be less work overall, and certainly less fiddling to get what I want. But I don’t even do that! I run pandoc --from=html --to=commonmark and then run everything through 15 lines of sed and then dump the results into a new file! Which I then automatically commit to Git!
Are there benefits to doing any of this? For a fool like me, absolutely. It’s easy to rg and fd my way to whatever intermediate file is choking my silly little news archive today.
Doing everything on a Raspberry Pi running cronjobs in my closet
“These aren’t that bad for projects of this small a scale.” Just you wait.
This Christmas I got a Raspberry Pi. I turned it on, tossed the same Ubuntu Server image I use for everything these days on it, and immediately dedicated 2 of its extremely expensive 4 gigs of RAM to a tmpfs. I have somewhere on the order of a dozen cronjobs on this thing which commit Git sins on a recuurring basis to this /ram, and the only reason I put it all in /ram in the first place was to avoid wearing down my SD card too quickly. Then another dozen or so which clone Git repos back down to /ram on startup.
It’s fast, it’s easy to work with, and it’s brittle as fuck. I paid money for this which could have gone into VTSAX. But I chose to be a silly man.
“Higher order” dependency management
Back in the day, when I knew little of the world, I did pip/apt-get install whatever and moved on with my life.
When a hasty emigration from the States forced me to adapt my CS hobby into an actual career or die trying, I spent some time trying to look more professional. I wrote Poetry, I committed every facet of Hypermodern Python to memory, I submitted a heavily overpackaged coding assignment to Wolt. And then I realized I could just as easily stick things in a Docker container and call it a day.
Now, knowing slightly more about the world, I do pip/apt install whatever.
If the day ever comes where I need to go further, I trust GPT-4 to eat my READMEs and poop out a nice tidy Dockerfile. To date, I have never needed to do this.
“Just use Python”-ing all the things
The day will come that I can hand off a Haskell / Scheme / Go / C# / Rust / Fish / Idris / Zig / JavaScript / TypeScript / Elm / OCaml / ReasonML / Coq / Agda / Lean / Scala / Java / Julia / Perl / PHP / SQL / Prolog / Smalltalk program to someone else I have never met before, explain nothing, and expect them to be able to figure it out. On that day I will praise the sun and get my small army of goblins in a damp cave to begin work on the New Testament of my work. Cleaner, faster, less prone to en-Pi-ification.
Until then, lingua franca goes brrr.
Using CC Zero whenever possible
I believe the public domain license reduces FUD and dead-weight loss, encourages copying (LOCKSS), gives back (however little) to Free Software/Free Content, and costs me nothing.
-Gwern, emphasis mine
Amen. Especially to that last part.
The culture that is the CLIzation of everything
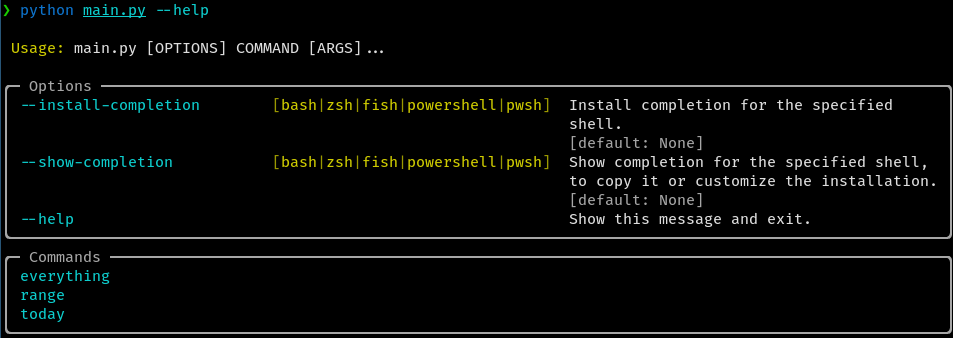
Above is the first draft of an actual program I am actually writing, to automatically generate flashcards from the JSON partly-refined aineita of one of those intermediate Git databases. Currently not one of those 3 commands actually does any flashcard generating.
And yet they are exactly what I want. I see this image and I know what the next 5 actions are going to be. Eventually this main.py will bloat to a 500 line monstrosity, just like all of my other projects, and I will think about maybe factoring it out into at minimum a separate cli.py and main.py, and then I will forget about it and move on with my life.
I understand many people will consider putting Minimum Viable CLIs around things to be a good pattern, not an anti-pattern. Not so! I do this because I know I don’t have the patience any more to write “real” web apps or “real” GUIs, which I myself never end up using, even if they make the project more accessible to 99% of the rest of the world.
I’m sorry. I will not change. Please forgive me my past and future trespasses. The spirit is willing, but the body is weak and needs to get back to his (handmade) flashcards now.
Comments